Around 6 million records with about 15 fields each.
This was the dataset that I wanted to analyze for a data analysis project of mine. But there was a big problem with its records; many were missing fields, and a lot of fields were either inconsistently formatted or outdated. In other words, my dataset was pretty dirty.
But there was some hope for the amateur data scientist in me - at least concerning the missing and outdated fields. Most records contained at least one hyperlink to an external website where I might find the information that I needed. So this looked like a perfect use case for a web crawler.
In this post, you'll find out how I built and scaled a distributed web crawler, and especially how I dealt with the technical challenges that ensued.
Early requirements
The idea of building a web crawler was exciting. Because, you know, crawlers are cool, right?
But I quickly realized that my requirements were much more complex than I had thought:
- Given a seed URL, the crawler needed to auto-discover the value of the missing fields for a particular record. So if a web page didn't contain the information that I was looking for, the crawler needed to follow outbound links, until the information was found.
- It needed to be some kind of crawler-scraper hybrid, because it had to simultaneously follow outbound links and extract specific information from web pages.
- The whole thing needed to be distributed, because there were potentially hundreds of millions of URLs to visit.
- The scraped data needed to be stored somewhere, most likely in a database.
- The crawler needed to work 24/7, so running it on my laptop wasn't an option.
- I didn't want it to cost too much in cloud hosting1.
- It needed to be coded in Python, my language of choice.
Okay, I had built and worked on many crawlers in my previous job, but nothing on the scale that I needed here. So this was entirely new territory for me.
Initial design
The design that I initially came up with was as follows:
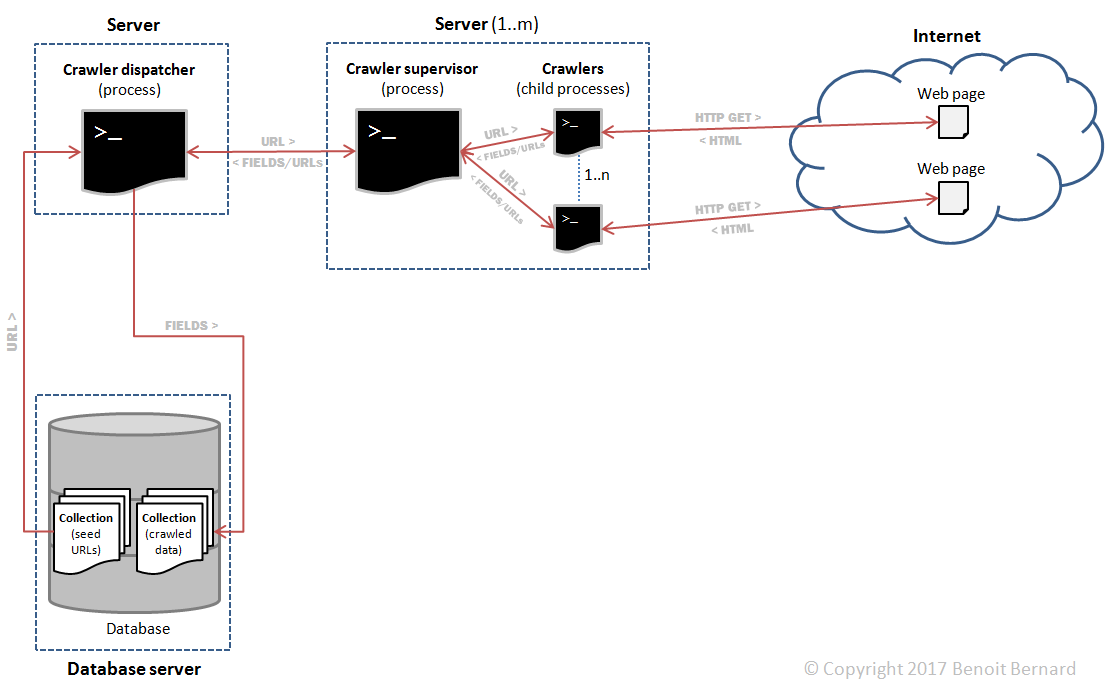
The main components were:
- A crawler dispatcher, responsible for dispatching URLs to be crawled to the m crawler supervisors, and for collecting results (fields) from them.
- m crawler supervisors, responsible for supervising n child processes. Those child processes would perform the actual crawling. I'll refer to them as crawlers for convenience.
- A database server, responsible for storing the initial seed URLs as well as the extracted fields.
So I would end up with m*n crawlers in total, thus distributing the load across many nodes. For example, 4 supervisors with 8 processes each would be equal to 32 crawlers.
Additionally, all interprocess communications across servers would happen thanks to queues. So in theory, it would be easily scalable. I could add more supervisors and the crawl rate - a performance metric - would increase accordingly.
Initial implementation
Now that I had a promising design, I needed to choose which technologies I would use.
But don't get me wrong here; my goal wasn't to come up with a perfect technology stack. Instead, I saw it mainly as a learning opportunity - and a challenge - so I was more than willing to come up with home-baked solutions, if needed.
1. Cloud hosting
I could have chosen AWS, but I was more familiar with DigitalOcean, which happens to be cheaper. So I used several 5$/month VMs (droplets).
2. HTTP library
The requests library is a no-brainer for performing HTTP requests in Python.
3. ETL pipeline
Sure, I needed to extract all hyperlinks from every visited web page. But I also needed to scrape specific data in some of those pages.
So I built my own ETL pipeline to be able to extract data and transform it in the format that I needed for my data analysis.
It was customizable via a configuration file as follows:
{
"name": "gravatar",
"url_patterns": [
{
"type": "regex",
"pattern": "^https?:\\/\\/(?:(?:www|\\w{2})\\.)?gravatar\\.com\\/(?!avatar|support|site|connect)\\w+\\/?$"
}
],
"url_parsers": [
{
"description": "URLs in the 'Find Me Online' section.",
"processors": [
{
"type": "xpath",
"parameters": {
"expression": "//h3[contains(text(), 'Find Me Online')]/following-sibling::ul[@class='list-details'][1]//a/@href"
}
}
]
},
{
"description": "URLs in the 'Websites' section.",
"processors": [
{
"type": "xpath",
"parameters": {
"expression": "//ul[@class='list-sites']//a/@href"
}
}
]
}
],
"fields": [
{
"name": "name",
"processors": [
{
"type": "xpath",
"parameters": {
"expression": "//div[@class='profile-description']/h2[@class='fn']/a/text()"
}
},
{
"type": "trim",
"parameters": {
}
}
]
},
{
"name": "location",
"processors": [
{
"type": "xpath",
"parameters": {
"expression": "//div[@class='profile-description']/p[@class='location']/text()"
}
},
{
"type": "trim",
"parameters": {
}
}
]
}
]
}
What you see above is a mapping for Gravatar user profile pages. It tells the crawler what data should be extracted from those pages and how:
- url_patterns defines patterns that are tentatively matched against the current page's URL. If there's a match, then the current page is indeed a Gravatar user profile.
- url_parsers defines parsers capable of extracting specific URLs in the page, like those pointing to a user's personal website or social media profile.
- fields defines the data that we want to retrieve from the page. For Gravatar user profiles, I wanted to extract the user's full name and location.
url_parsers and fields both contain a series of processors that are executed against the web page's HTML data. They perform transformations (XPath, JSONPath, find and replace, etc.) to get the exact data that I need, in the desired format. The data is thus normalized before it's stored somewhere else, which is especially useful because all websites are different and they represent data differently.
Manually creating all those mappings took me a lot of time, as the list of relevant websites was very long (hundreds of them).
4. Messaging
Initially, I wondered whether RabbitMQ would be a good fit. But I reasoned that I didn't want a separate server just to manage queues. I wanted everything to be lightning-fast and self-contained.
So I went with ZeroMQ push/pull queues, and I coupled them to queuelib's FifoDiskQueue to persist data to disk, in case a crash occurred. Additionally, using push/pull queues assured me that URLs would be dispatched to supervisors using a round-robin algorithm.
Figuring out how ZeroMQ works and understanding its several edge cases took me a while. But learning how to implement my own messaging was really fun and worth it in the end, especially performance-wise.
5. Storage
A good ol' relational database could have done the job. But I needed to store object-like results (fields), so I went with MongoDB.
Bonus points: MongoDB is rather easy to use and administer.
6. Logging and monitoring
I used Python's logging module, coupled with a RotatingFileHandler to generate one log file per process. This was especially useful to manage log files for the various crawler processes managed by each supervisor. And this was also helpful for debugging.
To monitor the various nodes, I didn't use any fancy tool or framework. I just connected to the MongoDB server every few hours using MongoChef and I checked that the average number of resolved records was going according to my calculations. If things slowed down, it most likely meant that something [bad] was going on, like a process crash or something else.
So yes - all blood, sweat and tears here.
7. Managing already crawled URLs
A web crawler is very likely to come upon the same URL more than once. But you generally don't want to recrawl it, because it probably hasn't changed.
To avoid this problem, I used a local SQLite database on the crawler dispatcher to store every crawled URL, along with a timestamp corresponding to its crawl date. So each time a new URL was coming up, the dispatcher searched the SQLite database for that URL to see whether it had already been crawled or not. If not, then it was crawled. Otherwise, it was ignored.
I chose SQLite because it's lightning fast and easy to use. And the timestamp accompanying every crawled URL was useful for debugging and reference purposes - in case someone would have filed a complaint against my crawler.
8. URL filtering
My goal wasn't to crawl the whole web. Instead, I wanted to auto-discover the URLs that I was interested in, and filter out those that were useless.
The URLs that I was interested in were whitelisted thanks to the ETL configuration introduced previously. And to filter out the URLs that I didn't want, I used the top 20K sites in Alexa's 1 million top sites list.
The concept is quite simple; any site appearing among the top 20K sites has a high probability of being useless, like youtube.com or amazon.com. However, based on my own analysis, any site beyond those top 20K sites has a much higher chance of being relevant to my analysis, like personal websites and blogs.
9. Security
I didn't want anyone to tamper with my DigitalOcean VMs, so:
- I blocked all ports on every VM by default using iptables. I also selectively unblocked the ports that I absolutely needed (80, 443, 22, 27017, etc.).
- I enabled SSL authentication on MongoDB, so only a user having a proper certificate could log into it.
- I used encrypted disks on all of my VMs.
- I enabled fail2ban on every VM to block repeatedly failed login requests.
- I configured SSH key-based authentication on all VMs.
- I enabled SSL authentication in ZeroMQ.
Okay, maybe I went a bit overboard with security :) But I did it on purpose; this was not only an excellent learning opportunity, but also a very effective way to secure my data.
10. Memory
A 5$/month DigitalOcean VM only comes with 512MB of memory, so it's fairly limited on what it can do. After many testing runs, I determined that all of my nodes should have 1GB of memory. So I created a swap file of 512MB on every VM.
Politeness... so what?
I was impressed by how fast I had been able to come up with a working implementation of my initial design. Things had been going smoothly, and my early testing runs showed impressive performance numbers (crawl rate) for my crawler. So I was pretty excited, to say the least!
But then, I came upon an article by Jim Mischel that completely changed my mind. As it turned out, my crawler wasn't "polite" at all; it was crawling web pages non-stop, with no restriction whatsoever. Sure, it had a very fast crawl rate, but it could have been banned by webmasters for the very same reason.
So what does politeness imply for a web crawler?
- It must identify itself via a proper user agent string.
- It must respect the rules of robots.txt.
- It must not send consecutive requests to websites too rapidly.
Should be fairly simple to implement, right?
Wrong. I quickly realized that the distributed nature of my crawler complicated things quite a bit.
Updated requirements
In addition to the requirements that I had already implemented, I also needed to:
- Create a page that described what my crawler was doing.
- Pass the User-Agent header in every HTTP request made by my crawler, and include a link to the explanation page that I created.
- Download robots.txt periodically for every domain, and check whether URLs were allowed to be crawled or not based on:
- The inclusion/exclusion rules.
- The Crawl-delay directive. In case it was absent, subsequent requests to the same domain needed to be spaced out by a conservative number of seconds (e.g. 15 seconds). This was to ensure that the crawler didn't cause an unexpected load on websites.
Bullet #3 was a bit more problematic, though. In fact, how could a distributed web crawler:
- Keep a single, up-to-date robots.txt cache, and share it with all workers (crawlers)?
- Avoid downloading robots.txt too frequently for the same domain?
- Track the last time that every domain has been crawled in order to respect the crawl-delay directive?
This implied some serious changes in my crawler.
Updated design
So here's the updated design that I came up with.

The main differences with the previous design were:
- Robots.txt would be downloaded for every domain.
- Robots.txt files would be cached in a database. Every hour or so, each file would be separately invalidated and redownloaded per domain, as needed. This was to ensure that the crawler would respect any changes made to robots.txt files.
- The last crawl date would be cached in a database for every domain as well. This would be used as a reference to respect the crawl-delay directive contained in robots.txt.
At this point, I feared that these changes would slow down my crawler. It almost certainly would, actually. But I didn't have a choice, or else my crawler would overburden websites.
Updated implementation
Everything that I had chosen so far stayed the same, except with a few key differences.
1. Handling of robots.txt
I chose the reppy library over urllib.robotparser because:
- It supports the crawl-delay directive.
- It automatically handles the download of expired robots.txt files.
- It supports directory inclusion rules (i.e. allow directives), as per Google's own implementation of robots.txt. Those rules are pretty common in robots.txt files found on the web.
So it was a no-brainer.
2. Caching of robots.txt and last crawl date
I added a second MongoDB server specifically dedicated to caching things. On the server, I created 2 distinct databases to avoid any potential database-level lock contention2:
- Database (1): held a collection containing the last crawl date for every domain.
- Database (2): held a collection containing a copy of robots.txt for every domain.
Additionally, I had to modify the reppy library a little bit, so that it cached robots.txt files in MongoDB instead of in memory.
Dealing with bugs and problems
I spent an awful lot of time debugging, profiling and optimizing my crawler during its development. Much more time than I had expected, actually.
Beyond the hangs3, memory leaks4, slowdowns5, crashes6 and various other bugs, I encountered a broad range of unexpected issues.
1. Memory management
Memory isn't an infinite resource - especially on a 5$/month DigitalOcean VM.
In fact, I had to limit how many Python objects were held at once in memory. For example, the dispatcher was pushing URLs to supervisors extremely fast - much faster than the latter could ever crawl them. At the same time, supervisors typically had 8 crawler processes at their disposal, so those processes needed to be constantly fed with new URLs to crawl.
So I set a threshold on how many URLs could be dequeued and held in memory at once on supervisors. This allowed me to strike a balance between memory usage and performance.
2. Bottlenecks
I quickly realized that I couldn't let my web crawler loose, or else it would have crawled the whole web - which wasn't my goal at all.
So I limited the crawl depth to 1, meaning that only seed URLs and their immediate child URLs would be crawled. This allowed my crawler to auto-discover most of the web pages that it was specifically looking for.
3. Dynamically generated content
I found that a lot of websites are dynamically generated using JavaScript. This means that when you download an arbitrary web page using a crawler, you might not have its full content. That is, unless you're capable of interpreting and executing its scripts to generate the page's content. To do this, you need a JavaScript engine.
Now, there are probably many ways to tackle this problem, but I settled on a very simple solution. I chose to dedicate some supervisors to crawling dynamically generated web pages only.
On those:
- I installed Google Chrome and Chrome Driver.
- I installed the Python bindings for Selenium.
- I installed Xvfb to simulate the presence of a monitor - because Chrome has a GUI, and CentOS has none by default.
So then, I had a few nodes capable of crawling dynamically generated web pages.
4. Edge cases
I already knew that building a regular crawler meant dealing with all sorts of weird API edge cases. But what about a web crawler?
Well, if you picture the web as an API, it's certainly a huge, crazy, vastly inconsistent one:
- Pages aren't all built in the same way.
- Pages often contain invalid characters (i.e. incompatible with the encoding of the page).
- Servers often return all kinds of HTTP errors (500, 404, 400, etc.), including custom ones (999, anyone?).
- Servers are often unreachable and cause timeouts. The domain/website might not exist anymore, or there might be DNS problems, or it might be under heavy load, or the server might be incorrectly configured or... You get the idea :)
- Some web pages are huge, like tens of megabytes or more7. This means that if you download them in one shot, and load them all into memory, you might very well run out of memory at some point8.
- Servers sometimes return incorrectly formed HTML markup, or non HTML content like JSON, XML or others. Who knows why!
- Web pages often contain invalid and incorrectly formed URLs. Or URLs that you just don't want to crawl, like large binary files (e.g. PDFs, videos, etc.).
The above is just a subset of the many problems that a web crawler needs to deal with.
Performance numbers
With a web crawler, you're normally interested in the crawl rate of your crawler, which is the number of web pages downloaded per second. For example, with 4 supervisors using 8 processes each, I estimated that my crawler was doing over 40 pages/second.
But I was much more interested in how many records of my original dataset were properly resolved per hour. Because, as mentioned previously, the original purpose of my crawler was to fill in the gaps in my dataset, either by fetching missing fields or refreshing outdated ones.
So with the same configuration as above, it was able to resolve around 2600 records per hour. A disappointing number for sure, but still good enough, considering that most web pages were useless and filtered out.
Future improvements
There are a few things that I'd do differently if I had to start all over again:
1. Messaging
I'd probably choose RabbitMQ or Redis over ZeroMQ mainly for convenience and ease of use, even if they're slower.
2. Monitoring/logging
I'd probably use tools like New Relic and Loggly to monitor the resources on my VMs and centralize logs generated by all nodes.
3. Design
I'd probably decentralize the robots.txt and last crawl date caches to improve the overall crawl rate. This means replacing MongoDB server #2 with caches stored locally on each supervisor, for every crawler process.
Here's the possible architecture:
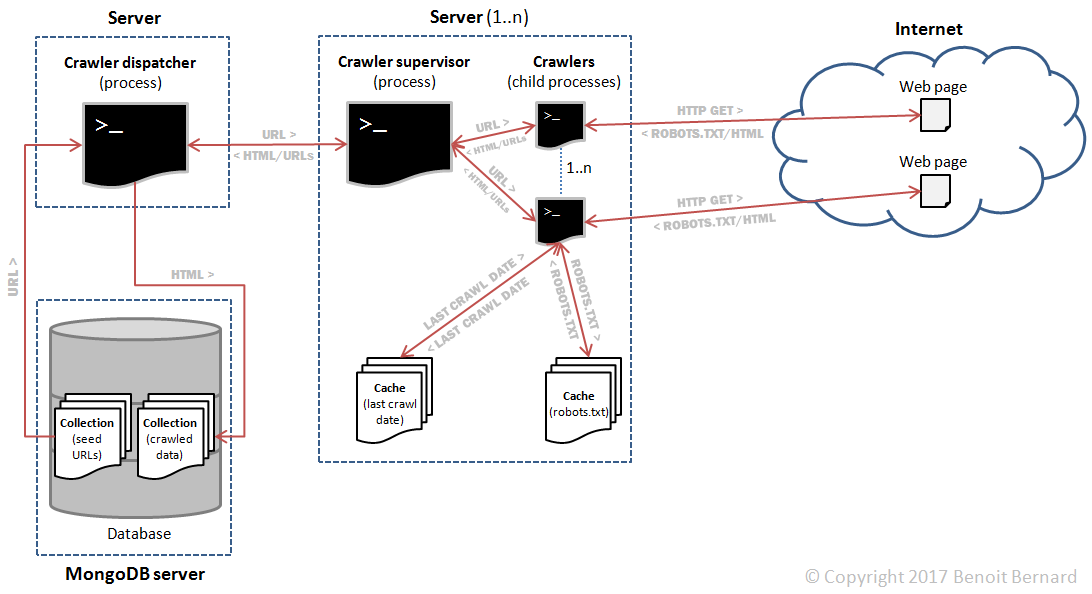
To summarize:
- On each supervisor node, each crawler process would have its own robots.txt and last crawl date caches; this would replace the centralized cache (MongoDB server #2).
- Due to this, the dispatcher would need to dispatch each URL to a very specific supervisor node.
- Upon receiving a new URL to crawl, a supervisor node would need to dispatch it to a very specific crawler process. Otherwise, multiple processes across different supervisors might crawl the exact same website at the same time. My crawler might then be banned, because it wouldn't be honoring the rules of robots.txt.
Fortunately, ZeroMQ supports prefix matching, so I could route a URL to a specific supervisor node based on its domain name. And I had already coded a persistent cache, mainly based on SQLite. So I could definitely reuse it to prevent individual caches from using too much memory.
Final thoughts
In this post, we've seen how I built a distributed web crawler to fill the gaps in a dirty dataset.
Initially, I wasn't expecting this project to become so huge and complex - which is probably what happens to most software projects.
But it really paid off in the end, because I learned a tremendous amount of things: distributed architectures, scaling, politeness, security, debugging tools, multiprocessing in Python, robots.txt, etc.
Now, there's one question left that I didn't answer in my post. Which dataset would justify all that work, exactly? What's the reason behind all of this?
This is what you'll find out in a future blog post!
P.S.: Feel free to leave your questions and comments in the comment section below!
Update (19/09/2017): this post was featured in Reddit. It was also featured in the Python Weekly, Pycoders Weekly and Programming Digest newsletters. If you get a chance to subscribe to them, you won't be disappointed! Thanks to everyone for your support and your great feedback!
Update (12/10/2020): this post now includes DigitalOcean referral links that will help me pay for the hosting of this blog. The idea is pretty simple - by clicking on those links, you automatically get 100$ in free VM credits once you sign up. And once you've spent 25$, I'll myself receive 25$ in VM credits. Pretty good deal, isn't it?
It only cost me 35$US (5$/month/VM * 7 VMs = 35$/month). This is why I briefly flirted with the idea of entitling my post A Poor Man's Guide to Creating a Distributed Web Crawler. ↩
In retrospect, having 2 different MongoDB databases was probably unnecessary. This is because write locks in MongoDB 3.0+ are apparently held per document, not per database. This appears to be contrary to versions prior to 3.0+, according to MongoDB's documentation and this Stackoverflow answer. ↩
This is why you need to download web pages by chunks. ↩
Some web pages are just designed that way. And others output an error message or stack trace that looks infinitely long. Either way, they're huge! ↩