Back in 2016, I had a crazy idea.
The annual Stack Overflow Developer Survey had just come out. And out of curiosity, I was contemplating how much work had been put into the survey. I mean, by the programmers themselves, but also by Stack Overflow's data scientists. I figured that it was a lot, somewhere close to 3.5 man-years of work in total1.
Also, I realized that only a small fraction of the total user base - more than 5.5 million in 20162 - had participated. So what if it didn't represent the community at large? Because it wasn't a completely random sample, obviously.
This is when I had an idea. What if the whole thing was... automated?
Disclaimer: I'm not affiliated with Stack Exchange Inc. My use of the Stack Overflow name is for practical purposes only and not to suggest that they endorsed or contributed to my post in any way.
Basic assumptions
The idea of automating the Stack Overflow Developer Survey was based on a core assumption:
Given a dataset comprised of all Stack Overflow users, I could automate and replicate the analysis done in the Stack Overflow Developer Survey but on a much larger scale.
A pretty wild claim, for sure. And this is why I needed to draw a line in the sand, because I probably couldn't automate the full survey at first, and with as much precision.
So I came up with two basic questions that I wanted to answer:
- Where are Stack Overflow users located in the world?
- What's the proportion of men and women among Stack Overflow users?
Of course, those questions could theoretically form the basis of many other questions. For example, based on the reputation score and the location of users, was there any talent pool hidden somewhere?
Requirements
My requirements were pretty simple to formulate based on my previous two questions:
- For each user, I should get their location expressed as geographic coordinates (latitude and longitude), so that I could put it on a map.
- For each user, I should get their gender (male or female).
I was now ready to begin.
Challenge 1: getting a proper dataset
It turns out that I had already heard of the Stack Overflow Data Dump. It's a copy of almost everything that you see on the site - questions, answers, votes... and user profiles.
So I downloaded the proper dump file and I glanced at it - it was one huge XML file (300MB+).
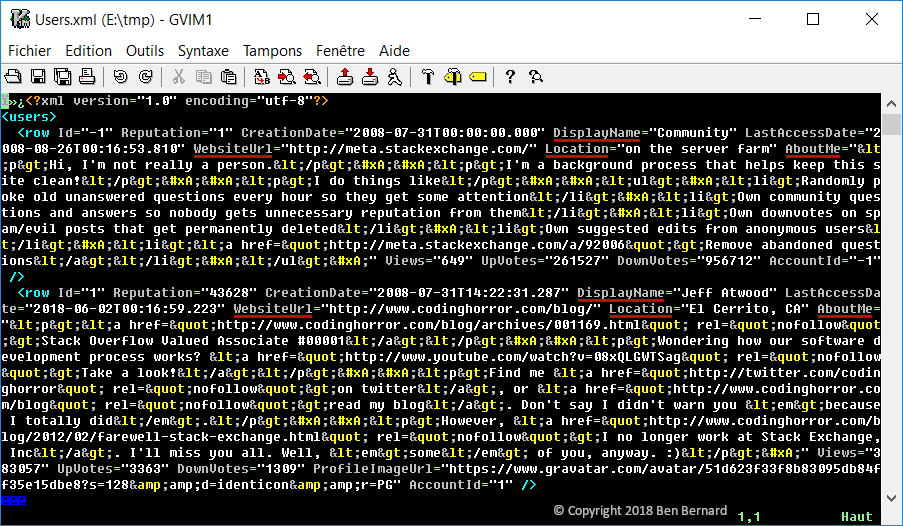
It certainly contained fields useful for my purpose: DisplayName, AboutMe, Location and WebsiteUrl.
But right away, I could tell that:
- Those fields were inconsistently formatted, mainly because they were free-text. So users could enter pretty much anything in whatever format they wanted.
- There was no field to identify a user's gender.
It was a bit disappointing for sure, but I felt that I wasn't completely out of luck.
Challenge 2: determining a user's location
To make the dataset a bit more manageable, I imported it in a local MongoDB database using a homemade Python script.
Then I had a closer look at the location field:
- It was often missing or blank, more than 75% of the time3.
- It was often inconsistently formatted (e.g. "San Jose, CA, United States", "1000 N 4th St, Fairfield, IA 52557", "Brasília - SP, Brasil", "90210", etc.).
- It was sometimes bogus or invalid (e.g. "Mars", "Earth", "my desk", "127.0.0.1", "https://twitter.com/the_user", etc.)
- It was sometimes very broad or ambiguous (e.g. "USA", "Portland", "Asia").
- It was sometimes outdated4.
So I would either have to normalize it, or to fetch it when it was blank, invalid or outdated - but how?
Well, thanks to the WebsiteUrl field (and URLs included in other fields), I could potentially search the user's personal blog or social media profile(s) for hints about their location.
Here's the initial algorithm that I came up with:
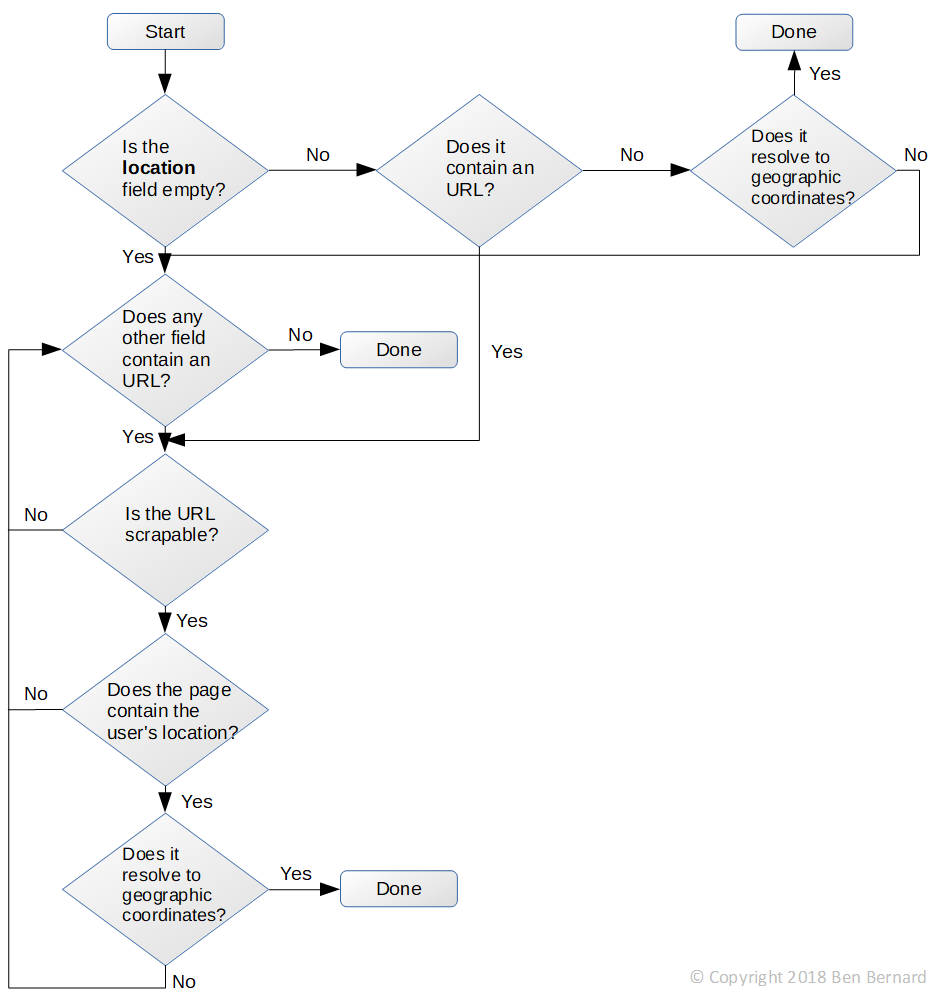
Basically, I'd have to analyze a user's Stack Overflow profile to find their location, or follow the URLs it contains to discover it. This assumed, of course, that the URLs would lead to scrapable web pages, that is pages having a predictable layout from which I could easily extract the information that I needed.
So yep, this was a perfect job for a web scraper.
Challenge 3: translating a user's location into geographic coordinates
Assuming that I'd be able to get a user's location, I'd then need to convert it to geographic coordinates. This process is called geocoding.
But there were 3 problems with geocoding APIs:
- Most were fairly expensive commercial products. For example, the price for resolving 1 million locations went up to several hundreds of dollars ($US)5.
- Most were quite limited in terms of quotas and speed. For example, most of them imposed hourly, daily and/or monthly limits on the number of allowed API requests.
- Many of them imposed severe restrictions - in terms of licensing - on the use of geocoded data6.
For these reasons, I briefly flirted with the idea of hosting my own geocoding service. A dream come true - no more limitations!
But I quickly found out that this was much more complicated than I thought. For example, I could have installed my own instance of the free and open-source OpenStreetMap Nominatim API. But for a "full planet import", I'd need 32GB of RAM and close to 800GB of disk space, which would far exceed my budget in infrastructure costs7. So back to square one.
This is when I found out about GeoNames. Their geocoding API allowed up to 30K free queries/day and imposed no major restrictions on the use of the geocoded data. Pretty nice!
So I started playing with the free API and I realized a few things:
- The data seemed reliable.
- But it was slow.
- And it imposed an hourly limit of 2000 queries. I could of course pay for a premium package to raise that limit, but I didn't want to pay up front for something that I wasn't sure would fit the bill.
It thus became clear that geocoding would be a major bottleneck in the algorithm that I had imagined. The rate at which locations could be extracted from web pages using a web scraper - let's say a distributed one - would be much greater than the rate at which they could be geocoded.
So one way or another, I'd need to cache the extracted or scraped user location for later processing.
Challenge 4: coming up with a better strategy
This is when I thought about something - why exactly did I try to resolve a user's location in a single pass?
I mean, I could first find a user's location independently of the geocoding step. That way, I could cache it or store it somewhere. And in a second pass, I could geocode that data.
But what if the extracted or scraped location was invalid, wrong or outdated?
Well, one possible strategy was to scan a user's profile and find every possible location candidate - be it from the Location field, or from the URLs included in the profile. And by applying some priority factor of my choosing to these locations, I could theoretically determine the one that was most likely right.
For example, I could use these priority factors8:
| Priority | Website |
|---|---|
| 1 | |
| 2 | GitHub |
| 3 | Keybase |
| 4 | |
| 5 | |
| 6 | |
| ... | ... |
| N | Stack Overflow |
So the higher a website appeared in that list, the most probable the user's location appearing on that website was the most up-to date. Of course, there would be cases where a user had moved and had not updated any of their social media profiles in a while. But I was ready to live with that.
Here's the algorithm split into two distinct steps9:
Naturally, I could default to the value of the Location field, in case no location could be determined from the URLs contained in the user profile.
Challenge 5: determining a user's gender
This part was a bit trickier because:
- A Stack Overflow user profile didn't specify any gender.
- Only a few social media platforms (e.g. Blogger, Google+, Sourceforge, Flickr, etc.) included that information.
So I'd have to guess the gender most of the time. But how?
Maybe I could have used some sophisticated machine learning algorithm to recognize a user's gender - you tell me. But I'm not an expert in that field.
There was an easy way out, fortunately. I could guess a user's gender based on their first name10. Sure, that might fail with unisex names (e.g. Alex, Casey, Jesse, etc.). But it would give reliable results most of the time. Cool!
So I could directly use the DisplayName field to get a user's full name, right?
Hum, no. Just look at these fine, real-world examples:
- fuenfundachtzig
- Ali_Abadani
- www
- saalon
- UberAlex
- Jeff Atwood
- Matt
- ...
You get the idea; the DisplayName field wasn't super reliable.
But it turns out that people often provide their full name on their personal blog or social media accounts. So just like user locations, I could scrape full names, too.
So I'd first need to scrape the user's full name candidates. And second, I'd have to guess the gender based on the first valid first name candidate.
Challenge 6: guessing a user's gender based on their first name
There were a few possible options here:
- gender-guesser: as good as it seemed to be, this Python package had a very restrictive license that would force me to publish my final dataset under a GNU Free Documentation License. I didn't want to do that, and it wasn't compatible with the Stack Overflow Data Dump's license.
- gender-detector: this Python package covered names from a handful of countries only. Canada wasn't even included!
- Genderize: this API had a free version that was very limited (1000 queries/day). Just like for geocoding, I didn't feel like paying up front for a service that might just not cut it.
Decidedly unsatisfied with these options, I initially chose to roll my own gender guesser. It wasn't all that complicated, but it required a lot of research for proper datasets, as first names are often tied to specific countries or regions.
So I started with the census data of Canada and USA11, and I came up with a reasonably well-working gender guesser. But I quickly realized that going through every possible country in the world would take a lot of time, and that it may not be worth it.
This is why, at this point, I decided to put this part on hold. And I told myself that once I'd have a database with the location and full name of every user, then I'd be able to revisit this issue and, possibly, reconsider Genderize.io.
Anyway, I knew that this was doable, technically.
Challenge 7: creating a web scraper
Now I had to retrieve the location and full name of every user.
The basic idea was to have some kind of web scraper that would use a mapping file. This mapping file would enumerate which websites it recognized, and for each one, it would list the XPath expressions necessary to scrape a user's location and full name. Pretty easy, right?
Well, not so much.
I encountered many technical challenges while implementing it. I also realized that:
- I needed a full ETL pipeline to retrieve and normalize data, not just an XPath engine12.
- My scraper had to follow hyperlinks contained in web pages, just like a regular web crawler does13.
- Because of that, I'd have to possibly visit millions of URLs. So my scraper had to be distributed, or else I'd be crawling forever.
But these problems were manageable. And I eventually got a fully working, distributed web scraper.
I ended up with a mapping file listing most websites of interest. For example, here's an excerpt for GitHub:
[
{
"name": "github",
"content_type": "static",
"url_patterns": [
{
"type": "regex",
"pattern": "^https?:\\/\\/(?:www\\.)?github\\.com\\/([\\w\\-]+)\\/?$"
}
],
...
"url_parsers": [
{
"description": "User's personal website.",
"processors": [
{
"type": "xpath",
"parameters": {
"expression": "//li[contains(@class, 'vcard-detail') and @itemprop='url']/a/@href"
}
}
]
}
],
"fields": [
{
"name": "name",
"processors": [
{
"type": "xpath",
"parameters": {
"expression": "//span[@itemprop='name']/text()"
}
}
]
},
{
"name": "location",
"processors": [
{
"type": "xpath",
"parameters": {
"expression": "//li[contains(@class, 'vcard-detail') and @itemprop='homeLocation']/text()"
}
}
]
}
]
},
...
]
Challenge 8: the big, bold wake-up call
Everything had been going well so far. Too well, maybe.
I was reading various blog posts about web crawlers and scrapers when I suddenly realized something important.
Yes, my scraper was polite. And I had received no complaints whatsoever following my early testing runs.
But it clearly didn't respect the terms of service (ToS) of many high-profile websites. More specifically, most of them prevented any form of scraping in terms similar to this:
You may not do any of the following while accessing or using the Services: [...] (iii) access or search or attempt to access or search the Services by any means (automated or otherwise) other than through our currently available, published interfaces that are provided by Acme (and only pursuant to those terms and conditions), unless you have been specifically allowed to do so in a separate agreement with Acme (NOTE: crawling the Services is permissible if done in accordance with the provisions of the robots.txt file, however, scraping the Services without the prior consent of Acme is expressly prohibited);
Additionally, I was possibly infringing their copyright. This was bad, really bad.
So I analyzed this from every possible angle:
- I created a page that explained the purpose of my scraper and how website owners could block it. And I included a hyperlink to it in my user agent string.
- I started reading the ToS of every website that I intended to scrape. And I then selectively removed the riskiest ones from my mapping file... which turned out to be the majority.
- I considered asking for a written permission to all websites that I intended to scrape. But this wasn't realistic - there were too many of them, and I felt that many would turn me down or take a long time to reply.
- I asked for advice to other programmers that I know. Some told me that giving up was a wise choice, whereas others suggested that I use proxies to "hide" my activities - but I wasn't comfortable with that at all, as I didn't want to hide anything.
Deep inside me, I knew that I was desperately trying to justify what I was doing. I was trying to work around well-established limitations.
This was really frustrating.
But after reading stories like Pete Warden almost being sued by Facebook for data scraping, and LinkedIn actively suing people who scrape user profiles (see here and here), I decided that, well, maybe I should just give up.
Final thoughts
This post described my failed experiment in automating the Stack Overflow Developer Survey.
Automating it - at least part of it - is technically possible. I was able to come up with almost all the needed parts.
But for legal reasons, I had to give up, and before it was too late.
I know that this is disappointing. I was extremely disappointed myself.
But let's look at the bright side; this was just an experiment. Not only did I learn a massive amount of things in the process, but I also had a lot of fun.
And well... why not repurpose my scraper for something else?
Update (09/10/2018): this post was featured in the Programming Digest newsletter. If you get a chance to subscribe to it, you won't be disappointed!
Update (12/10/2020): this post now includes one DigitalOcean referral link that will help me pay for the hosting of this blog. The idea is pretty simple - by clicking on that link, you automatically get 100$ in free VM credits once you sign up. And once you've spent 25$, I'll myself receive 25$ in VM credits. Pretty good deal, isn't it?
This was a highly hypothetical and simplified calculation. I assumed that: (56033 developers who participated * 0.5 hours to answer the poll) + (1 data scientist * ~160 hours of work) = 3.22 years. ↩
This is an approximation based on this page: https://stackoverflow.com/users ↩
To be more precise, the June 2018 data dump reveals that 77.5% of users didn't specify a location. ↩
Stack Overflow users don't seem to update their profile all that much, but I found that it's another story for their other social media profiles. ↩
I found that the MapQuest Open Search (Nominatim) API was the most expensive at 900$US for 500K queries/month. It also had a very restrictive license. The cheapest option was the OpenStreetMap Nominatim API - it was free. But it clearly mentioned that you couldn't use it for purposes like mine (i.e. resolving locations in bulk). ↩
Back in 2016, the Google Geocoding API's license prevented us from displaying geocoded data anywhere else than on a Google Map. Since then, things have changed, fortunately. ↩
Back in 2016, as per this pricing page, a DigitalOcean VM with 32GB of RAM and 800GB of disk space would have cost me: 320$US/month + (800GB * 0.10$US/GB/month) = 400$US/month. ↩
I chose that priority order based on empirical evidence. For example, I noticed that Stack Overflow users tend to keep their location current on their LinkedIn, GitHub and Keybase profiles, but not so much on either Facebook or Stack Overflow, interestingly. This is why the former appear before the latter in the list. ↩
The Google Maps-like icon that I used in this diagram was made by Chamestudio Pvt Ltd and is available under a Creative Commons (Attribution 3.0 Unported) license. ↩
I subsequently found out that this is similar to the method suggested by some PhD students in their paper titled Recognizing Gender of Stack Overflow Users. ↩
The census data of the US is pretty well organized for first names. But for Canada, each province does its own census and it stores data in its own way - which can be stored in text files, web pages, Excel files or CSV files. ↩
This was because the full name and location of users were often oddly formatted in web pages. ↩
The websites linked to from inside Stack Overflow user profiles were often blogs that didn't contain the information I was looking for, but that did contain hyperlinks to the users' social media profiles. ↩